I haven’t got a chance yet to play with asynchronous I/O APIs in any production
application so, to fill in that gap I’ve decided to commit some time and
experiment with posix AIO and liburing a try. These two are (I think?),
at the time of writing, the two most popular APIs to perform
asynchronous operations in Linux.
This post isn’t a benchmark nor a comparison between the two. It’s just a
knowledge summary of the basics behind using these APIs and what I’ve learned
along the way.
POSIX aio
Warning
aio APIs should not be used for production purposes. The kernel
implementation for the underlying APIs is not available - as a result, aio is
implemented using thread pools in glibc. aio works only in O_DIRECT mode. The
APIs don’t scale well and usage may lead to disappointing performance.
aio is comprised of a set of APIs very similar to traditional synchronous
APIs we all know and use all the time. The most prominent ones:
aio_read
aio_write
aio_error
aio_return
aio_suspend
You work with these APIs using a control block (struct aiocb). Control block is a structure
which describes an I/O operation to perform. The general workflow looks the
following way:
Setup the control block,
Call aio_read or aio_write with the control block as an argument (this enqueues the I/O operation),
Wait for operation to complete (by polling on aio_error, suspending the calling thread using aio_suspend or setting a signal handler),
Get the I/O operation’s result using aio_result - this returns exactly the same data as synchronous write or read would return,
Operation is done. To enqueue more operations go to 1.
Here’s a very simple program, showing the basic usage of aio APIs:
#include<aio.h>#include<errno.h>#include<string.h>#include<stdlib.h>#include<fcntl.h>#include<unistd.h>#include<stdio.h>constchar*statusAsString(ints){switch(s){caseEINPROGRESS:return"in progress";caseECANCELED:return"cancelled";case0:return"completed";}return"error";}intmain(){charbuffer[256]={0x00};intinfd=open("/etc/hostname",O_RDONLY);// declare and setup the control block
structaiocbcb;memset(&cb,0,sizeof(cb));cb.aio_fildes=infd;cb.aio_buf=buffer;cb.aio_nbytes=sizeof(buffer);cb.aio_sigevent.sigev_notify=SIGEV_NONE;// schedule asynchronous read
aio_read(&cb);// synchronously wait for the operation to complete
conststructaiocb*constaiocb_list[]={&cb};aio_suspend(aiocb_list,1,nullptr);close(infd);// check the operation status
intstatus=aio_error(&cb);if(0>status){perror("aio_read");returnEXIT_FAILURE;}// get operation's results
intnbytes=aio_return(&cb);printf("Aio status: %s, transfered: %d bytes\n",statusAsString(status),nbytes);printf("Contents: [%s]\n",buffer);returnEXIT_SUCCESS;}
Of course, you wouldn’t want to use asynchronous APIs like that - in a
synchronous fashion. This is where completion notifications come into play.
Completion notification can be set using sigev_notify field within the control block.
There are 3 values that sigev_notify can be set to:
SIGEV_NONE - no notifications issued on completion,
SIGEV_SIGNAL - signal will be raised on completion,
SIGEV_THREAD - new thread will be spun-up running a function given in sigev_notify_function
The third one would be most optimal but spinning up threads on I/O completion
is expensive and will kill the performance so, the only usable option is the
signal notification. This is a bit problematic as only a limited set of
functions are safe to be used from within a signal handler. Looking at man 7 signal-safety only these, belonging to aio family, are allowed:
aio_error(3)
aio_return(3)
aio_suspend(3)
This is a bit too limiting as, most often, on I/O completion you want to
schedule another operation (like scheduling aio_write with the data returned
by prior aio_read result). There’s a clean way out - signalfd. Have a look on the example:
In the thread reading from signalfd I can call any function I want.
Additionally, it’s worth mentioning that I’m using a real time signal as the
notification signal specifically because of one reason - real time signals are
queued.
It’s becoming obvious why aio is not the preferred choice for asynchronous
I/O API. This simple example is performing a single request yet it’s requiring
a significant boiler plate. Additionally, for brevity, I’ve kept error
handling to minimum.
More complete example with AIO and signalfd
You might remember that I’ve already covered signal handling with signalfd in
one of my previous posts. Back then, I’ve created a simple library -
libsignals to simplify working with signals and file descriptors. I’m
gonna use this library now to implement an example program which is closer in
its completeness to a real application and will allow for some rudimentary
performance testing.
To kick things off, I’ve prepared the following program skeleton:
#include<fcntl.h>#include<unistd.h>#include<cstdlib>#include<iostream>#include<memory>#include<thread>#include<signals/factory.h>#include<signals/scoped_sigset.h>#include<signals/signal_handler_callbacks.h>#include<signals/sigset_util.h>namespace{constintIoSignal=SIGRTMIN;}// namespace
voidusage(constchar*progname){std::cout<<progname<<": <pool-size> <bufsize> <input> <output> <mb>"<<std::endl;}classTransfer:publicsignals::SignalHandlerCallbacks{public:Transfer(std::size_tpoolSize,std::size_tbufSize,std::string_viewinput,std::string_viewoutput,std::size_tmb):bufSize{bufSize},readSchedPos{0},total{mb*1024*1024},ops{std::make_shared<signals::RealFdOps>()},inFd{open(input.data(),O_RDONLY),ops},outFd{open(output.data(),O_WRONLY|O_CREAT),ops}{}boolonSignal(constsignals::SigInfo&si)override{returnfalse;}voidinitiate(){// TODO: to be implemented
}voidwait(){// TODO: to be implemented
}private:conststd::size_tbufSize;std::size_treadSchedPos;std::size_twriteCompPos;conststd::size_ttotal;std::shared_ptr<signals::FdOps>ops;signals::ScopedFdinFd;signals::ScopedFdoutFd;};intmain(intargc,constchar*argv[])try{if(6!=argc){usage(argv[0]);returnEXIT_SUCCESS;}std::size_tmbs=std::strtoul(argv[5],nullptr,10);std::size_tpoolSize=std::strtoul(argv[1],nullptr,10);std::size_tbufSize=std::strtoul(argv[2],nullptr,10);signals::ScopedSigSetsss{signals::createFullSet()};autotransfer=std::make_unique<Transfer>(poolSize,bufSize,argv[3],argv[4],mbs);autotransferRaw=transfer.get();autofactory=std::make_unique<signals::SignalHandlerFactory>();autosigSet=signals::createSet(IoSignal,SIGTERM,SIGINT);autosigHandler=factory->createSignalFdHandler(sigSet,std::move(transfer));std::jthreadsigThread{[&](){sigHandler->run();}};transferRaw->initiate();transferRaw->wait();returnEXIT_SUCCESS;}catch(conststd::exception&e){std::cerr<<e.what()<<std::endl;}catch(...){std::cerr<<"Unknown exception caught"<<std::endl;}
This program takes the following CLI arguments:
pool-size - this is the amount of control-blocks pre-allocated, used to perform simultaneous asynchronous I/O operations, in other words, it defines the number of asynchronous operations in flight at the same time,
bufsize - each control block will be associated with its own buffer, this argument defines the buffer size,
input/output - these two are self explanatory - these are just paths to files acting as the data source and destination,
mbs - this the number of megabytes that will be transferred from input to output. I want to define it separately to be able to experiment with /dev/zero and similar pseudo-devices like that.
I’ve paired the control blocks with buffers to form a descriptor:
voidscheduleRead(Desc&desc,std::size_toffset,std::size_ttoTransfer){if(0==toTransfer){return;}if(autor=desc.aioRead(inFd.get(),offset,toTransfer);r!=0){throwstd::runtime_error("Failed to schedule read transfer");}}voidscheduleRead(Desc&desc){constautotoTransfer=calcTransferSize();scheduleRead(desc,readSchedPos,toTransfer);readSchedPos+=toTransfer;}voidinitiate(){std::lock_guardl{m};readSchedPos=0;for(autoit=pool.begin();it!=pool.end();++it){scheduleRead(*(*it));}}
From this point onwards, the whole transfer will be self sustaining. Once the
aio_read completion signal arrives, with the data in the aio_read
descriptor I can proceed with aio_write. Similarly aio_write completion
can trigger another aio_read to maintain data flow. This will spin until the
requested amount of data is transferred. Here’s how the signal handler looks:
boolonSignal(constsignals::SigInfo&si)override{boolisComplete=false;if(IoSignal==si.sigNo){auto*desc=Desc::fromUserData(si.sentPtr);if(!desc){std::cerr<<"received signal with no context"<<std::endl;returnfalse;}if(!desc->isComplete()){throwstd::runtime_error("completion signal received but operation is not complete");}constautonBytes=static_cast<std::size_t>(desc->aioReturn());if(nBytes==0){std::cerr<<"operation didn't perform any io"<<std::endl;returnfalse;}if(desc->wasRead()){// read operation completed, perform a write with obtained data
if(desc->getSize()>nBytes){std::cout<<"Short read, scheduling partial read"<<std::endl;auto&newDesc=pool.emplace_back(std::make_unique<Desc>(bufSize));autooffset=desc->getOffset()+nBytes;autosize=desc->getSize()-nBytes;scheduleRead(*newDesc,offset,size);}scheduleWrite(*desc,nBytes);}else{// write operation completed, schedule another read
std::lock_guardl{m};writeCompPos+=nBytes;isComplete=(writeCompPos==total);if(!isComplete){if(desc->getSize()<nBytes){std::cout<<"Short write, scheduling partial write"<<std::endl;autooffset=desc->getOffset()+nBytes;autosize=desc->getSize()-nBytes;scheduleWrite(*desc,offset,size);auto&newDesc=pool.emplace_back(std::make_unique<Desc>(bufSize));desc=newDesc.get();}scheduleRead(*desc);}}}if(isComplete){cv.notify_one();}return(SIGTERM==si.sigNo||SIGINT==si.sigNo||isComplete);}
io_uring was designed with performance in mind. This is de-facto a goto
async I/O solution for Linux at the time of writing. io_uring is built
around a single producer, single-consumer ring buffers acting as a communication
channels between the user space program and the kernel itself.
There are two ring buffers. One for SQEs (submission queue entries) and one
for CQEs (completion queue entries). In simple terms, you schedule I/O
requests on sqe and wait for their completion on cqe - that’s it. No
signals, extra threads spun up on completion, so on and so forth. You define
your threading model yourself.
io_uring APIs are modelling standard synchronous APIs. Before submitting an
I/O request, it has to be prepared. io_uring equivalents to traditional
synchronous read/write APIs are io_uring_prep_read and
io_uring_prep_write. There are APIs for vectorised scatter/gather I/O
(readv/writev and preadv/pwritev) operations and socket operations
equivalents as well. The API is quite extensive and I’m only scratching the surface here.
I’m gonna focus on most basic use cases only - just to show basic principles
behind the APIs. Here’s how to perform a single read:
#include<liburing.h>#include<stdio.h>intmain(){structio_uringring;std::size_tsize=4;intflags=0;io_uring_queue_init(size,&ring,flags);intinfd=open("/etc/hostname",O_RDONLY);structio_uring_sqe*sqe=io_uring_get_sqe(&ring);charbuffer[64];std::size_toffset=0;io_uring_prep_read(sqe,infd,buffer,sizeof(buffer),offset);// You can prepare a batch of requests here and use a single //
// `io_uring_submit` to submit them all at once.
io_uring_submit(&ring);structio_uring_cqe*cqe=nullptr;io_uring_wait_cqe(&ring,&cqe);intnBytes=cqe->res;if(nBytes<0){perror("read");return-1;}// mark cqe as processed
io_uring_cqe_seen(&ring,cqe);printf("Transfered: %d bytes\n",nBytes);printf("Contents: %s\n",buffer);close(infd);io_uring_queue_exit(&ring);return0;}
For the sake of comparison, I’ve implemented a similar program as for aio,
using io_uring - transferring data between two files. I’ve created a
small RAII wrapper to manage the io_uring_queue:
classUring{public:explicitUring(intqueueSize):queueSize{queueSize}{unsignedflags=0;if(autor=io_uring_queue_init(queueSize,&ring,flags);r!=0){throwstd::runtime_error("Failed to setup queue");}}~Uring(){io_uring_queue_exit(&ring);}structio_uring*get()noexcept{return˚}structio_uring_sqe*getSqe(){returnio_uring_get_sqe(&ring);}intsubmit(){returnio_uring_submit(&ring);}private:intqueueSize;structio_uringring;};
In a similar vein, I’ve created a descriptor as well which mostly abstracts the I/O operation and its associated buffer:
voidinitiate(){for(auto&desc:descs){scheduleRead(desc);}if(ur.submit()<0){throwstd::runtime_error("Failed submitting read events");}}boolscheduleRead(Desc&desc,std::size_toffset,std::size_ttoTransfer){if(0==toTransfer){returnfalse;}if(offset>total){std::stringstreamss;ss<<"Read offset ("<<offset<<") outside of transfer size ("<<total<<")";throwstd::runtime_error(ss.str());}structio_uring_sqe*sqe=ur.getSqe();if(nullptr==sqe){throwstd::runtime_error("Failed to obtain submit queue event for reading");}desc.setIsRead(true);desc.setOffset(offset);desc.setSize(toTransfer);io_uring_prep_read(sqe,inFd.get(),desc.get(),toTransfer,offset);io_uring_sqe_set_data(sqe,&desc);returntrue;}boolscheduleRead(Desc&desc){constautotoTransfer=calcTransferSize();autor=scheduleRead(desc,readPos,toTransfer);if(readPos<total){readPos+=toTransfer;}returnr;}std::size_tcalcTransferSize()const{constautoremainingTotal=total-readPos;returnstd::min(remainingTotal,bufSize);}
Completion and follow up requests are now done on the same thread in wait:
voidwait(){while(writtenPos<total){structio_uring_cqe*cqe;if(autor=io_uring_wait_cqe(ur.get(),&cqe);r!=0){throwstd::runtime_error("Failed waiting for cqe");}Desc*desc=reinterpret_cast<Desc*>(io_uring_cqe_get_data(cqe));if(nullptr==desc){throwstd::runtime_error("CQE has no user data");}if(cqe->res<0){std::stringstreamss;ss<<"Read transfer failed: "<<::strerror(std::abs(cqe->res));throwstd::runtime_error(ss.str());}constautonBytes=static_cast<std::size_t>(cqe->res);if(0==nBytes){io_uring_cqe_seen(ur.get(),cqe);continue;}if(desc->isRead()){if(nBytes<desc->getSize()){// short read
Desc&newDesc=descs.emplace_back(bufSize);constautooffset=desc->getOffset()+nBytes;constautoremaining=desc->getSize()-nBytes;scheduleRead(newDesc,offset,remaining);}scheduleWrite(*desc,nBytes);if(ur.submit()<0){throwstd::runtime_error("Failed submitting write event");}}else{// Write operation completed.
writtenPos+=nBytes;if(nBytes<desc->getSize()){// short write
Desc&newDesc=descs.emplace_back(bufSize);constautooffset=desc->getOffset()+nBytes;constautoremaining=desc->getSize()-nBytes;scheduleWrite(newDesc,offset,remaining);}if(scheduleRead(*desc)){if(ur.submit()<0){throwstd::runtime_error("Failed submitting read event");}}}io_uring_cqe_seen(ur.get(),cqe);}// while
}voidscheduleWrite(Desc&desc,std::size_toffset,std::size_ttoTransfer){structio_uring_sqe*sqe=ur.getSqe();if(nullptr==sqe){throwstd::runtime_error("Failed to obtain submit queue event for writing");}if(offset>total){std::stringstreamss;ss<<"Write offset ("<<offset<<") outside of transfer size ("<<total<<")";throwstd::runtime_error(ss.str());}desc.setIsRead(false);desc.setSize(toTransfer);io_uring_prep_write(sqe,outFd.get(),desc.get(),toTransfer,offset);io_uring_sqe_set_data(sqe,&desc);}voidscheduleWrite(Desc&desc,std::size_ttoTransfer){scheduleWrite(desc,desc.getOffset(),toTransfer);}
For comparison, the entire program is available on gitlab as
well.
Splicing
The test program I’ve written using aio and io_uring APIs could be
optimised to avoid copying data buffers between kernel and user space. That’s
what splice(2) is for.
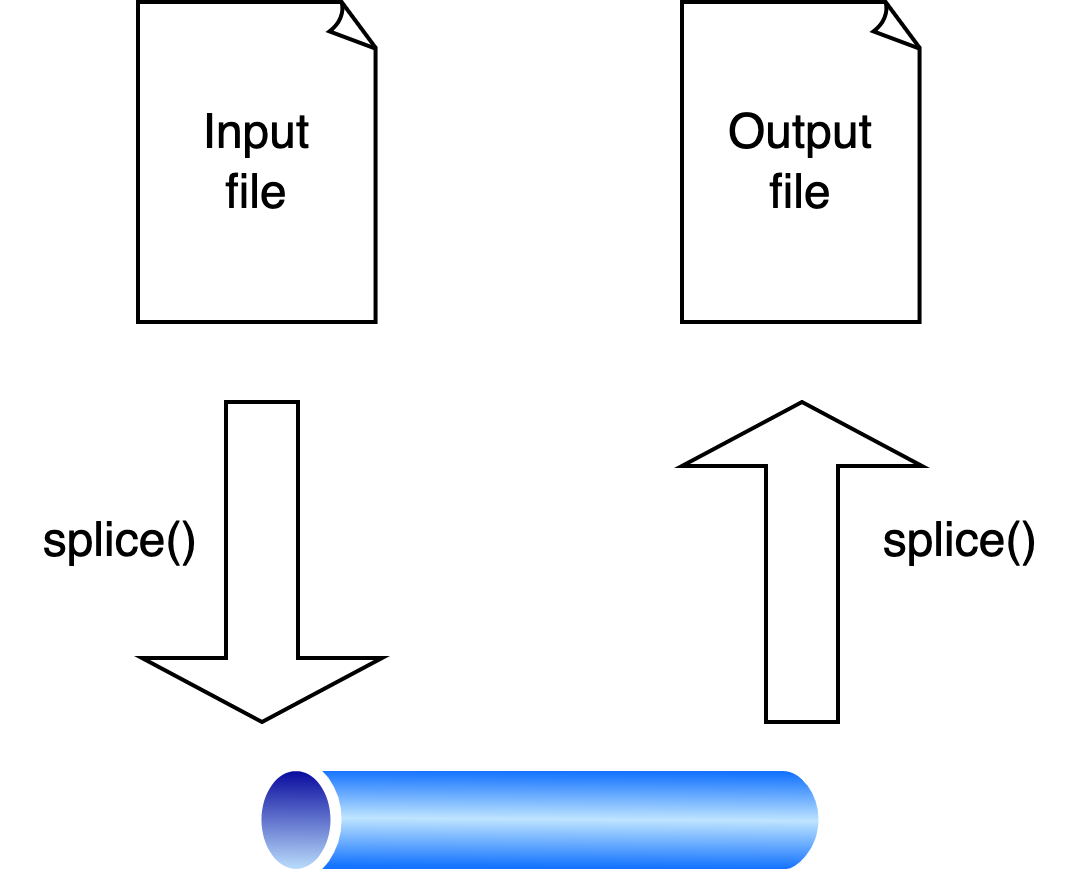
splice transfers data between two file descriptors but requires one of them
to be pipe(2) file
descriptor. With splice, my test program can be rewritten to perform the
following:
How splicing works.
Synchronous version could be written like so (error handling omitted for brevity):
voidtransfer(std::string_viewinput,std::string_viewoutput,std::size_tchunkSize,std::size_tmb){intpipefd[2];intinfd=open(input.data(),O_RDONLY);intoutfd=open(output.data(),O_WRONLY);off_treadPos=0;off_twritePos=0;constsize_ttotal=mb*1024*1024;pipe2(pipefd,O_CLOEXEC);while(static_cast<std::size_t>(writePos)<total){intnRead=splice(infd,&readPos,pipefd[1],nullptr,chunkSize,0);readPos+=nRead;intnWritten=splice(pipefd[0],nullptr,outfd,&writePos,chunkSize,0);writePos+=nWritten;}// close pipe
close(pipefd[0]);close(pipefd[1]);// close file descriptors
close(infd);close(outfd);}
There’s also
copy_file_range(2)
which transfers data between file descriptors and doesn’t need a pipe but I’m
not gonna focus on it as there’s no asynchronous equivalent (at least as far as
I know) available in io_uring.
io_uring provides an implementation of asynchronous splice. Writing an
async version using splice is a bit tricky. In essence, splice reads data from
the file and then shares the underlying kernel buffer with the pipe. In other
words, there’s now one buffer, which is append only. Reading concurrently from
multiple offsets all at once won’t be possible as the ordering of the data in
the pipe may not be preserved. This means that asynchronous version only
decouples the act of starting the I/O from its completion but functionally
remains synchronous to maintain proper sequencing.
That being said, the differences between my first io_uring example and the
one using splice are rather limited. Within initiate I’m just initiating one transfer:
boolscheduleRead(Desc&desc,std::size_toffset,std::size_ttoTransfer){if(0==toTransfer){returnfalse;}if(offset>total){std::stringstreamss;ss<<"Read offset ("<<offset<<") outside of transfer size ("<<total<<")";throwstd::runtime_error(ss.str());}structio_uring_sqe*sqe=ur.getSqe();if(nullptr==sqe){throwstd::runtime_error("Failed to obtain submit queue event for reading");}desc.setIsRead(true);desc.setOffset(offset);desc.setSize(toTransfer);io_uring_prep_splice(sqe,inFd.get(),offset,pipe.getWriteEnd().get(),-1,toTransfer,0);io_uring_sqe_set_data(sqe,&desc);returntrue;}boolscheduleRead(Desc&desc){constautotoTransfer=calcTransferSize();autor=scheduleRead(desc,readPos,toTransfer);returnr;}
There are similar changes within scheduleWrite but I advise you to refer to
the full source for more details.
Basic benchmarks
I need to start with a short disclaimer. I’m running these tests on a
relatively old machine (i5-6300U) with SATA3 SSD so, these results in general
might be underwhelming when compared to new hardware. Additionally, the drive
is LUKS encrypted which, for sure, impacts writes performance noticeably on top
of that.
Let’s start with a baseline. I’ve chosen the block size to be 64k to
correspond with the CPU’s L1 cache size. Here are the results I’m gonna
compare my tests against.
1
2
3
4
$ dd if=/dev/zero of=/dev/null bs=$((64*1024))count=$((4*16*1024))status=progress
65536+0 records in
65536+0 records out
4294967296 bytes (4.3 GB, 4.0 GiB) copied, 0.366778 s, 11.7 GB/s
Write performance:
1
2
3
4
5
dd if=/dev/zero of=data4g bs=$((64*1024)) count=$((4*16*1024)) status=progress
4065067008 bytes (4.1 GB, 3.8 GiB) copied, 6 s, 723 MB/s
65536+0 records in
65536+0 records out
4294967296 bytes (4.3 GB, 4.0 GiB) copied, 6.18258 s, 695 MB/s
Read performance:
1
2
3
4
5
dd if=data4g of=/dev/null bs=$((64*1024)) count=$((4*16*1024)) status=progress
4151771136 bytes (4.2 GB, 3.9 GiB) copied, 8 s, 519 MB/s
65536+0 records in
65536+0 records out
4294967296 bytes (4.3 GB, 4.0 GiB) copied, 8.31217 s, 517 MB/s
Read/write performance:
1
2
3
4
5
dd if=data4g of=data4g-2 bs=$((64*1024)) status=progress
4290052096 bytes (4.3 GB, 4.0 GiB) copied, 19 s, 226 MB/s
65536+0 records in
65536+0 records out
4294967296 bytes (4.3 GB, 4.0 GiB) copied, 20.9207 s, 205 MB/s
I’m dropping the caches between every test!
1
echo 3 | sudo tee /proc/sys/vm/drop_caches
Expected results
The underlying performance should remain the same, regardless of the API used
as it should remain I/O device bound (SSD - in case of pseudo-device and SSD
transfers or between two files on the SSD).
I guess what I’m trying to verify is if usage of one API introduces any
differences in CPU overhead when compared to other APIs.
Reading from /dev/zero and writing to /dev/null throughput
AIO
Test command (this transfers 16GB between /dev/zero and /dev/null in chunks
of 64KB with 32 scheduled I/O operations at minimum at once - I’ve fined tuned
the parameters to reach best results).
Transfer rate: 1820.44 MB/s
Command being timed: "./bld/aio_example 32 65536 /dev/zero /dev/null 16384"
User time (seconds): 6.61
System time (seconds): 9.51
Percent of CPU this job got: 170%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:09.44
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 6104
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 8
Minor (reclaiming a frame) page faults: 687
Voluntary context switches: 921456
Involuntary context switches: 1192
Swaps: 0
File system inputs: 1528
File system outputs: 0
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
This is a bit disappointing. Just shy of 2GB/s compared to a similar test
done with dd which yield almost 12 GB/s.
io_uring
Test command (this transfers 32GB between /dev/zero and /dev/null in chunks
of 64KB with 8 prepared and submitted requests to SQE at minimum at once - I’ve
fined tuned the parameters to reach best results).
Transfer rate: 10922.7 MB/s
Command being timed: "./bld/io_uring_example 8 65536 /dev/zero /dev/null 32768"
User time (seconds): 0.85
System time (seconds): 2.69
Percent of CPU this job got: 99%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:03.56
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 5856
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 11
Minor (reclaiming a frame) page faults: 635
Voluntary context switches: 22
Involuntary context switches: 40
Swaps: 0
File system inputs: 2312
File system outputs: 0
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
This is much better and comparable to the baseline in terms of throughput. The
test programs were not written with extra care for optimisation so some
performance degradation is completely expected.
The time results are interesting as well when compared to aio test.
Signifficantly less context switches - most likely related to lack of signal
handler and extra thread and in overall the fact that the app is much simpler.
io_uring splice
splice doesn’t work with /dev/zero and yields EINVAL.
Reading from /dev/zero and writing to SSD throughput
AIO
Test command (this transfers 4GB from /dev/zero to SSD in chunks
of 64KB with 32 scheduled I/O operations at minimum at once - I’ve fined tuned
the parameters to reach best results).
Transfer rate: 455.111 MB/s
Command being timed: "./bld/aio_example 32 65536 /dev/zero data4g 4096"
User time (seconds): 1.34
System time (seconds): 5.07
Percent of CPU this job got: 69%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:09.30
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 7868
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 8
Minor (reclaiming a frame) page faults: 685
Voluntary context switches: 181605
Involuntary context switches: 5091
Swaps: 0
File system inputs: 1512
File system outputs: 8388608
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
io_uring
Test command (this transfers 8GB from /dev/zero to data8g SSD in chunks
of 64KB with 8 prepared and submitted requests to SQE at minimum at once - I’ve
fined tuned the parameters to reach best results).
Transfer rate: 431.158 MB/s
Command being timed: "./bld/io_uring_example 8 65536 /dev/zero data8g 8192"
User time (seconds): 1.24
System time (seconds): 10.75
Percent of CPU this job got: 62%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:19.19
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 738912
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 8
Minor (reclaiming a frame) page faults: 183917
Voluntary context switches: 155569
Involuntary context switches: 14985
Swaps: 0
File system inputs: 2176
File system outputs: 16777216
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
This is a bit slower than the baseline but it basically saturates the SSD
bandwidth which as expected is a bottleneck here. What stands out is the
maximum resident set size (RSS) which is almost x100 bigger than for aio test
program (really not sure why).
io_uring splice
splice doesn’t work with /dev/zero and yields EINVAL.
Reading from SSD and writing to /dev/null throughput
AIO
Test command (this transfers 16GB between SSD file and /dev/null in chunks
of 64KB with 32 scheduled I/O operations at minimum at once - I’ve fined tuned
the parameters to reach best results).
Transfer rate: 496.485 MB/s
Command being timed: "./bld/aio_example 32 65536 data16g /dev/null 16384"
User time (seconds): 5.99
System time (seconds): 16.15
Percent of CPU this job got: 66%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:33.48
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 6088
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 8
Minor (reclaiming a frame) page faults: 679
Voluntary context switches: 861580
Involuntary context switches: 720
Swaps: 0
File system inputs: 33552112
File system outputs: 0
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
The results are a bit lower than the baseline. Similar story as before in
regards to the rest of the measurements - high CPU utilisation, lots of context
switches etc.
io_uring
Test command (this copies 16GB from SSD to /dev/null in chunks
of 64KB with 8 prepared and submitted requests to SQE at minimum at once - I’ve
fined tuned the parameters to reach best results).
Transfer rate: 528.516 MB/s
Command being timed: "./bld/io_uring_example 8 65536 data16g /dev/null 16384"
User time (seconds): 0.76
System time (seconds): 7.91
Percent of CPU this job got: 27%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:31.14
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 4440
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 11
Minor (reclaiming a frame) page faults: 282
Voluntary context switches: 129397
Involuntary context switches: 362
Swaps: 0
File system inputs: 33557016
File system outputs: 0
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
Similarly as with the converse case (writing to SSD from /dev/zero) this is SSD
bound which is confirmed by low CPU utilisation. This time RSS is comparable to aio.
io_uring splice
Test command (this copies 16GB from SSD to /dev/null in chunks
of 64KB with 8 prepared and submitted requests to SQE at minimum at once - I’ve
fined tuned the parameters to reach best results).
Transfer rate: 481.882 MB/s
Command being timed: "./bld/io_uring_splice_example 65536 data16g /dev/null 16384"
User time (seconds): 1.44
System time (seconds): 11.17
Percent of CPU this job got: 36%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:34.52
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 3812
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 8
Minor (reclaiming a frame) page faults: 160
Voluntary context switches: 1169536
Involuntary context switches: 9612
Swaps: 0
File system inputs: 33556488
File system outputs: 0
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
It’s worth noting that the majority of CPU time has been spent in system.
Reading from SSD and writing to SSD throughput
In all cases, as expected, the throughput is halved and again, as expected
fully limited by the SSD itself.
AIO
Test command (this copies 4GB between two SSD files in chunks
of 64KB with 32 scheduled I/O operations at minimum at once - I’ve fined tuned
the parameters to reach best results).
Transfer rate: 240.941 MB/s
Command being timed: "./bld/aio_example 32 65536 data8g data4g 4096"
User time (seconds): 1.77
System time (seconds): 8.79
Percent of CPU this job got: 60%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:17.54
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 6092
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 8
Minor (reclaiming a frame) page faults: 678
Voluntary context switches: 202819
Involuntary context switches: 1035
Swaps: 0
File system inputs: 8390648
File system outputs: 8388608
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
io_uring
Test command (this copies 4GB between two files on SSD in chunks
of 64KB with 8 prepared and submitted requests to SQE at minimum at once - I’ve
fined tuned the parameters to reach best results).
Transfer rate: 256 MB/s
Command being timed: "./bld/io_uring_example 8 65536 data8g data4g 4096"
User time (seconds): 0.38
System time (seconds): 8.78
Percent of CPU this job got: 54%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:16.90
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 4448
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 11
Minor (reclaiming a frame) page faults: 282
Voluntary context switches: 90801
Involuntary context switches: 1102
Swaps: 0
File system inputs: 8391464
File system outputs: 8388608
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
io_uring splice
Test command (this copies 4GB between two files on SSD in chunks
of 64KB with 8 prepared and submitted requests to SQE at minimum at once - I’ve
fined tuned the parameters to reach best results).
Transfer rate: 240.941 MB/s
Command being timed: "./bld/io_uring_splice_example 65536 data8g data4g 4096"
User time (seconds): 0.38
System time (seconds): 6.74
Percent of CPU this job got: 40%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:17.67
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 4064
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 11
Minor (reclaiming a frame) page faults: 155
Voluntary context switches: 293094
Involuntary context switches: 352
Swaps: 0
File system inputs: 8391400
File system outputs: 8388608
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
Conclusion
As initially stated, I haven’t yet had a practical need to refer to any of
these APIs in production solutions. It’s good to know though how each of these
APIs work and how to use them, as well as have some results from on-hands
experiments.
I guess that I’ve managed to confirm that AIO is probably not
the best candidate API for asynchronous I/O outside of the realm of
experimentation and, io_uring is something I’d go for. The io_uring APIs are
rich, easy to use and indeed yield good performance.
As the main use-case for these APIs is really high performance network
applications, it would be useful to gain some practical experience in that area
by experimentation as well but that’s a topic for another day :).
As always, example programs are available on gitlab.